

The Five Layers of Cloud Maturity Inside a Bank — Where Does Yours Sit?
A diagnostic framework to see where your cloud function sits and what closes each gap.
TLDR
Banking cloud maturity is not a single dimension. A bank can be sophisticated in infrastructure automation but immature in security governance. Advanced in operations but fragile on foundations. This post maps cloud maturity across five interdependent layers: Foundations (policies, guardrails, baseline infrastructure), Security (controls, threat detection, vulnerability management), Automation (infrastructure-as-code, deployment pipelines, self-service), Operations (observability, incident response, resilience), and Value Delivery (platform product, application velocity, business outcomes). Most banks sit at different maturity levels across these layers. The gaps between layers—not the absolute position in any single layer—tell you where to invest first.
This is post four of a series on cloud engineering and leadership in financial institutions. Post one covered why cloud in a bank is nothing like cloud anywhere else: the operating model shift that prudential obligations demand. Post two explored what nobody tells you when you become a cloud lead: the identity shift from technical expert to governance leader. Post three dove into how to read APRA's prudential standards as design constraints: connecting regulation to architecture. This post maps where your cloud function sits across five dimensions of maturity.
The maturity conversation nobody's having
It's week three of a board risk review. The CRO is holding a spreadsheet. Columns: cloud workloads, availability zones, backup frequency, encryption status. All green. The CIO describes the platform team's work: policy-as-code, landing zones, automated compliance scanning.
Then a director asks the question that destabilises the room: "You have good architecture and you clearly have good tooling. But if I move a business-critical application onto this platform today, how fast can I deploy it? How quickly can I get observability? Can I run chaos engineering tests? And if something goes wrong at 3am, who's on call and what's their runbook?"
Silence.
The spreadsheet was measuring infrastructure. The question was about capability. They are not the same thing.
This is the gap that maturity models expose. Not gaps in technology. Gaps in orchestration between layers of capability.
A bank might have excellent infrastructure but immature operations. Or sophisticated security controls that slow deployment velocity. Or operational excellence that masks fragile foundations underneath.
The question is not "how mature is your cloud?" It is "where is maturity uneven, and what does that fragmentation cost you?"
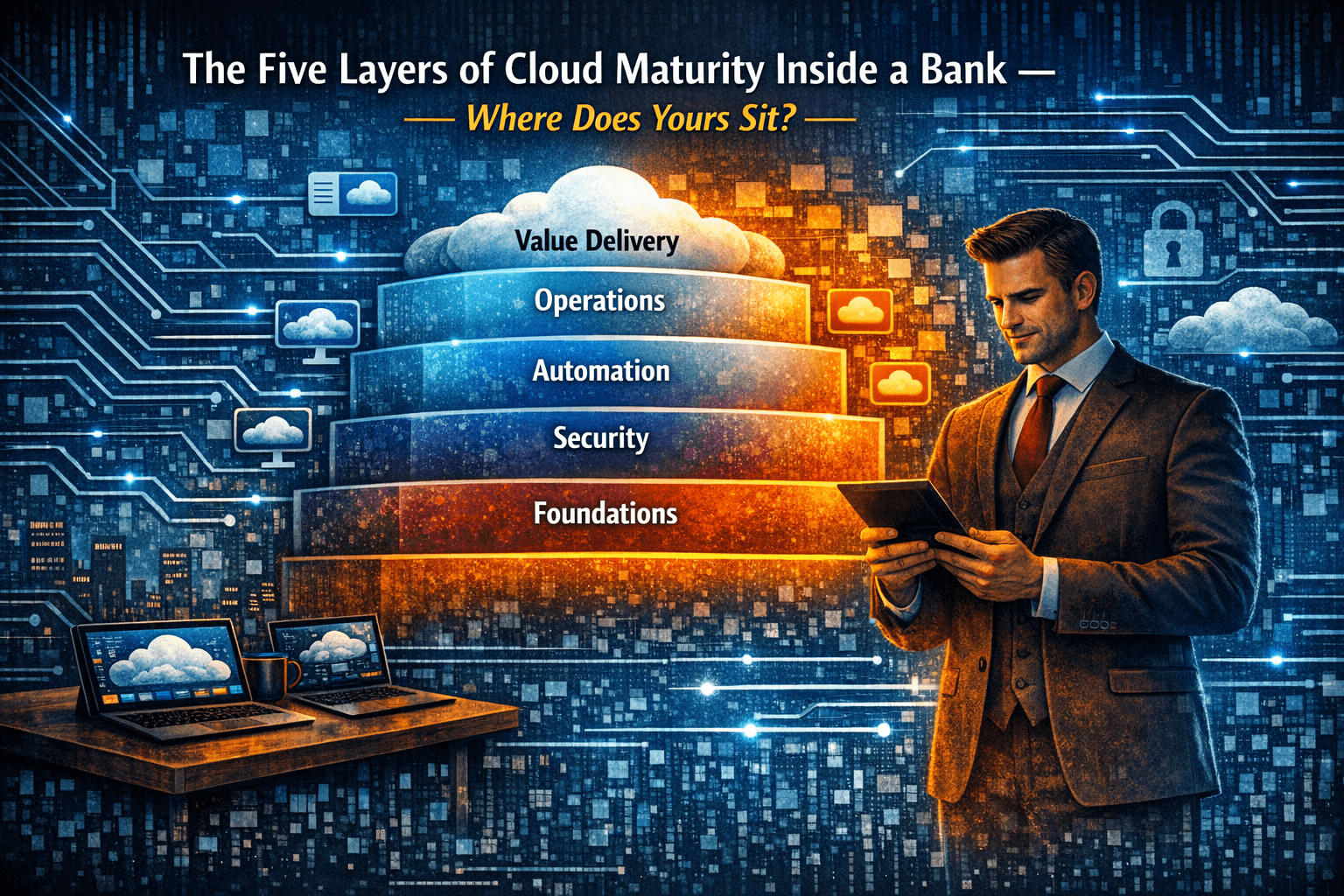
The five layers: what matters in banking cloud
Cloud maturity in a regulated environment is not a single ascending path. It is five simultaneous tracks, each necessary, each interdependent, each vulnerable to being carried by the others.

Figure 1: The five maturity layers. Each layer builds on the previous. Weakness in any one layer constrains the ones above.
Layer 1: Foundations
The baseline infrastructure your other four layers rest on.
Foundations are about structure, not speed. A multi-tier landing zone that encodes governance into architecture. Centralized platform controls that make safe defaults the path of least resistance. A subscription/account strategy that isolates blast radius and aligns to operational accountability. Baseline encryption, network segmentation, identity boundary separation. A policy-as-code framework that blocks non-compliant deployments before they happen.
In the first post in this series, we called this "prudential engineering." Encoding governance into architecture so doing the right thing is structurally easier than the wrong thing.
Foundations maturity means:
Workloads cannot be provisioned outside your policy envelope, even if a developer tries
Every resource inherits encryption, network isolation, and audit logging by default
The blast radius of any single team's mistake is bounded by their tier
Your architecture is defensive, not hopeful
Most banks have basic foundations or are building them. Few have mature foundations where policy operates continuously without human intervention, where drift is automatically remediated, and where exceptions require structural override rather than workaround approval.
Layer 2: Security
Controls that operate continuously, not seasonally.
Security in banking is not a CAB gate or an annual audit. It is a continuous operating discipline. CPS 234 demands information security controls proportionate to risk, tested with frequency commensurate to that risk, and producing continuous evidence they're working.
That is not a security team running a quarterly scan. That is a control built into the deployment pipeline, enforced at provisioning time, drifting detected in real-time, and violations escalated without human intervention.
Security maturity means:
Encryption configuration is policy-enforced, not documented
Threat detection is continuous (CSPM/CNAPP at scale), not periodic
Vulnerability management is automated from scanning to remediation signal
Access controls (who can do what to which resources) are role-enforced, audited, and reviewed quarterly
Security testing is shift-left into the deployment pipeline (secrets scanning, SAST, container image scanning before deploy)
Incident response includes detection SLAs, escalation paths, and regulatory notification timing built into runbooks
Immature security often looks like this: strong controls on paper, auditable by third parties, but operating through manual processes.
A vulnerability scan runs quarterly. Network segmentation is documented but not enforced by policy. Encryption exists but customers can disable it. Secrets are managed but no real-time detection catches sprawl.
The gap between documented controls and continuously-enforced controls is where banking cloud fails at security maturity.
This vulnerability doesn't show up until pressure arrives.
Layer 3: Automation
Infrastructure-as-code, deployment velocity, and self-service platforms.
Automation is about velocity without abandoning safety.
A mature platform tier owns the guardrails (policy-as-code, module libraries, approved patterns). Application teams use that platform to deploy with minimal friction, inheriting compliance by default.
This is where everything breaks if foundations are weak. If your landing zone is ad hoc, you cannot scale platform self-service without chaos. If your policy framework is not enforced, teams will work around it. Automation maturity depends on foundational maturity.
Automation maturity means:
Infrastructure is code-defined, versioned, and deployed through CI/CD pipelines
A team can deploy a new application with guardrails pre-applied in under an hour
Deployment failures are deterministic and debuggable, not mysterious
Rollback is automatic and tested (not a prayer)
Approved patterns exist as reusable modules; teams are not writing Terraform from scratch
Multi-environment promotion (dev → staging → production) is automated
Immature automation looks like: manual resource creation, "it worked in my subscription" deployments, surprise infrastructure changes, runbook-dependent deployments with heroic fixes at 3am.
The threshold question for this layer: How long from "I want to deploy a new service" to "it is live in production with observability and backups"? Mature automation makes that under 2 hours. Ad hoc approaches make that 2–4 weeks.
Layer 4: Operations
Observability, incident response, and the ability to maintain critical operations within tolerance.
Operations is where regulatory obligations become real.
CPS 230 demands not just that critical operations are defined and have tolerance levels, but that they stay within tolerance during disruption. That demand is operationally different from a standard incident response. It requires defined incident classification, escalation triggers tied to tolerance levels, runbooks scoped to time budget, and evidence that the system can hold under stress.
Operations maturity means:
Every application has defined SLOs, error budgets, and consequence-aware incident severity levels
Observability covers it all: metrics, logs, traces, and alert routing happen automatically by tagging policy
Incident response is time-scoped: detection SLA, initial response SLA, escalation SLA, regulatory notification SLA
Business continuity testing happens quarterly, not theoretically
Failover has been practiced and timed, not assumed
Post-incident reviews are blameless and produce actionable changes, not process theater
Immature operations look like: best-effort monitoring, incident response by email thread, SLOs as aspirations not constraints, disaster recovery plans that have never been tested, observability scattered across five different tools with no unified incident classification.
The operational consequence of immaturity is simple: When pressure arrives, teams rely on heroism and tribal knowledge rather than documented, time-budgeted runbooks.
Layer 5: Value Delivery
Platform product, application velocity, and business outcomes.
The layers below value delivery are infrastructure. This layer is strategy. A mature platform is treated as a product: it has SLAs defined by tenant needs, onboarding runways, a service catalogue that describes what workload types fit where, and metrics that show whether application teams are faster on the platform than off it.
Immature platforms feel like: teams using cloud in spite of the platform, not because of it. Application teams waiting for cloud to do unblocking, repeatedly asking for the same self-service capability, workarounds being more common than approved paths.
Value delivery maturity means:
The platform is a known, tested place to run production workloads, not an experiment
Application teams know what workload types fit your cloud (where should legacy databases run, where should AI inference services run?)
A new workload can discover the right landing spot, identify the necessary controls, and engage the right support without tribal knowledge
Business leaders see cloud adoption as enabling outcomes, not as a cost center
The business question this layer answers: Are you building application velocity by making cloud frictionless, or are you asking engineering teams to subsidize cloud adoption by jumping through complexity gates?
Where most banks sit (and why the gaps matter)
Most banks are not uniformly mature. They are uneven. Here's a common pattern:
Strong Foundations + Weak Operations. You have a well-architected landing zone, policy-as-code, solid security controls. But incident response runbooks assume someone knows what to do. Observability is fragmented. SLOs are documented but not enforced. Result: The platform is safe but not trustworthy at 3am.
Mature Automation + Immature Security. Teams can deploy quickly. Foundational controls are solid. But security controls are auditable, not continuous. A vulnerability scan runs quarterly. Real-time threat detection is not baked into the platform. Result: Velocity without continuous safety.
Excellent Operations + Immature Value Delivery. Your platform is reliable, observable, incident-ready. But application teams still build on-premises infrastructure because your platform's service catalogue doesn't match their needs. Or the onboarding runway is too long. Result: You have a magnificent platform that enterprise teams avoid.
Fragmented Across All Five. This is most banks. Foundations are decent. Security is improving. Automation is partial. Operations is... complicated. Value delivery is what we hope happens. Result: Cloud is a tool, not a capability.

Figure 2: Three common gap patterns. Each pattern creates different operational consequences. The diagonal is where you want to be: uniform maturity across all five layers.
The question for your leadership is not "how mature is our cloud?" It is "where are the gaps, and which gap costs us most in operational risk, velocity, or business outcomes?"
The three traps that keep banks uneven
Trap 1: Confusing "mature in one layer" with "mature in all layers"
You have excellent observability and incident response (Operations mature). That does not mean your deployment automation is sophisticated (Automation might be weak). Excellence in one layer does not lift the others. Each layer requires deliberate investment.
Trap 2: Skipping a layer because "it's not the bottleneck yet"
Building automation on weak foundations fails when you scale. Building value delivery on immature operations fails when disruption arrives. Some layers must lead. Others follow. The sequencing matters.
Trap 3: Treating maturity as a reporting metric instead of a operational risk indicator
"We are Level 3 in security" tells an audit nothing actionable. "Our threat detection operates in real-time with <5min mean time to detection and violations are auto-escalated" tells you whether the control actually works. Maturity is diagnostic, not cosmetic.
Diagnostic assessment: Where are you actually?
Use these questions to map your bank's maturity across the five layers. For each layer, answer yes or no. Where you have five nos, that is a gap worth addressing first.
Foundations
[ ] Can a team not provision resources outside your policy envelope, even if they try hard? (Is policy-as-code blocking non-compliant deployments?)
[ ] Does every workload automatically inherit encryption, network isolation, and audit logging by design, not by choice?
[ ] If a team makes a mistake in their subscription, is the blast radius bounded by the tier they're in?
Security
[ ] Do you have continuous threat detection running across all cloud environments, producing alerts in real-time?
[ ] Is vulnerability scanning automated, with a defined remediation SLA tied to severity?
[ ] Can you demonstrate that your information security controls (all of them) were operating effectively yesterday and will do so today?
Automation
[ ] Can a team deploy a new production service with guardrails pre-applied in under 4 hours?
[ ] Is infrastructure-as-code the default path, or is manual provisioning still common?
[ ] If a deployment fails, can a team understand why from logs without asking a platform engineer?
Operations
[ ] Does every business-critical service have an SLO defined with a consequence-aware incident severity model?
[ ] Can you run a chaos engineering scenario and demonstrate that the system recovers within tolerance?
[ ] Can you demonstrate the time from "incident detected" to "regulatory notification sent" fits within your defined SLAs?
Value Delivery
[ ] Do application teams deploy to your platform faster than they deploy elsewhere? (Not "as fast as," faster.)
[ ] Can a new application team identify the right landing spot for their workload without asking three people?
[ ] Are you growing cloud adoption because teams want to use the platform, or because you are mandating it?
For each layer, count the yeses. A layer with two or fewer yeses is immature and probably causing friction elsewhere.
What closes each gap
This is where the series branches. Future posts will deep-dive on the specific investments that close each gap. For now, the pattern:
Foundations gaps close through landing zone re-architecture and policy-as-code maturation. (Coming in Blog 5)
Security gaps close through continuous control enforcement, threat detection automation, and real-time vulnerability management. (Deep dive coming on CPS 234 and CSPM/CNAPP integration.)
Automation gaps close through IaC discipline, CI/CD standardization, and modular platform patterns.
Operations gaps close through end-to-end observability, SRE cadence, and tested business continuity processes.
Value delivery gaps close through platform product thinking: treating your internal cloud capability as a service with defined SLAs, service tiers, and tenant feedback loops.
Each gap has different lead time, different dependencies, different team ownership. The gaps are not independent.
The real question: Which gap closes first?
Maturity models are diagnostic. They show you where you are. But they do not show you where to start.

Figure 3: The progression model. Identify your highest-friction gap, close it, and iterate. Each closed gap reveals the next bottleneck. Uniform maturity emerges through repeated cycles, not master planning.
Start with whichever gap creates the most operational friction:
If the safety bottleneck is security controls that are auditable but not continuous, close the security gap.
If the velocity bottleneck is teams deploying manually because automation requires tribal knowledge, close the automation gap.
If the risk bottleneck is operations teams unable to respond to incidents within your defined SLAs, close the operations gap.
If the business bottleneck is application teams avoiding your platform because it is not tailored to their workload types, close the value delivery gap.
The first gap to close is the one strangling you today. The others will become apparent once the first one opens space.
The One Architecture Decision That Controls Everything Else (Blog 5 Deep Dive)
Earlier in this series, we explored why banking cloud is fundamentally different, what a cloud lead actually does, and how to read prudential regulation as a design constraint.
This framework is the reference architecture for everything that follows. Each future post will deep-dive on one gap, one layer, one operational pattern that matters at scale.
But here's the hard truth: the next post tackles the one decision that determines whether all four layers above it can succeed or are doomed to fail. Your landing zone architecture. Get it wrong, and your security layer, operations layer, and value delivery layer will all be fighting against your foundation. Get it right, and every team that comes after you inherits resilience, compliance, and safety by default.
Blog 5 shows you how to engineer a landing zone that encodes governance into architecture so deeply that doing the wrong thing becomes structurally impossible.
Where does your cloud program sit on this maturity model? And more importantly—which gap is costing you the most operational risk or engineering velocity today?


